
Automatische Use Case Identifikation in umfassenden Anforderungsspezifikationen
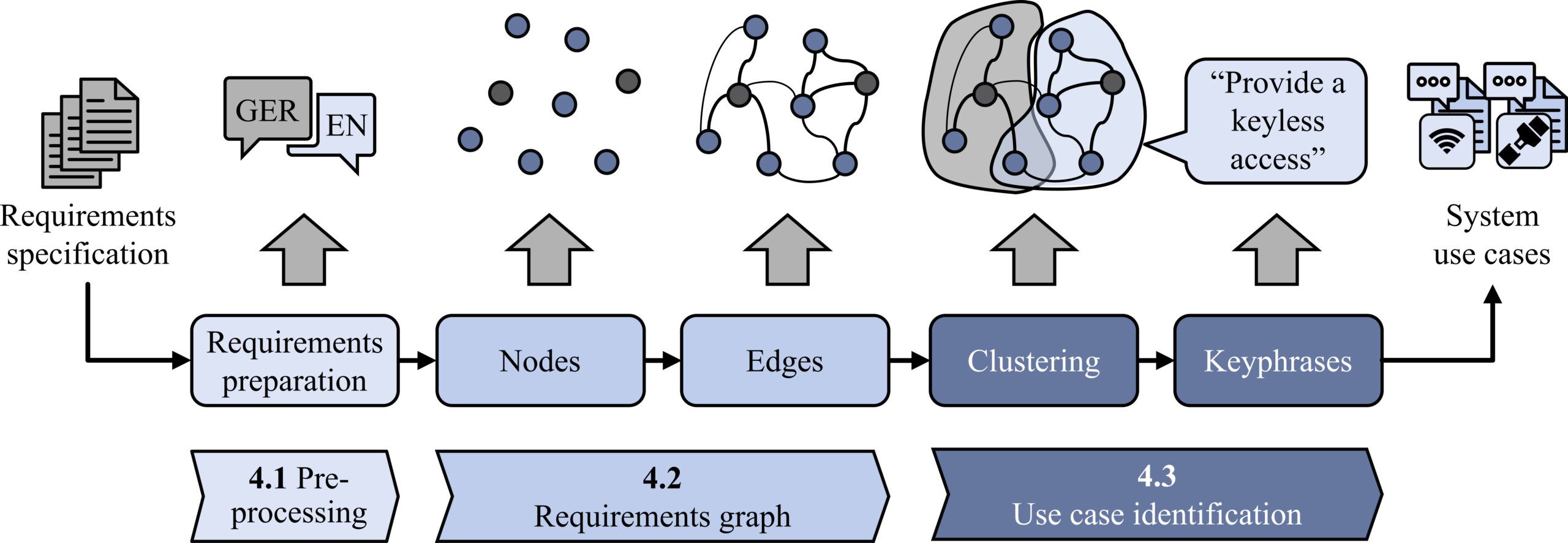
Die Entwicklung komplexer Produkte ist gekennzeichnet von immer umfassenderen Anforderungsspezifikationen. Um diese strukturiert in der Produktentwicklung zu berücksichtigen, werden oftmals Use Cases eingesetzt. Da deren manuelle Identifikation gerade in sehr großen Anforderungsspezifikationen extrem zeitaufwendig ist, haben wir am KTmfk eine neuartige, KI-gestützte Methode entwickelt. Im Kern steht ein Anforderungsgraph, der sich aus Embeddings der Anforderungstexte und deren semantischer Ähnlichkeit aufbaut. Zusätzlich können bereits bestehende, manuelle Verbindungen zwischen zusammengehörigen Anforderungen berücksichtigt werden, was in eine halbüberwachte Graph-Erstellung mündet. Auf diesem Anforderungsgraphen werden anschließend geeignete Clustering-Algorithmen angewendet, um die einzelnen Use Cases effizient zu identifizieren. Die Nachvollziehbarkeit wird für den Ingenieur zusätzlich über aussagekräftige Zusammenfassungen der Use Cases erhöht. Mit diesem Ansatz liefert der KTmfk einen wertvollen Beitrag für die Handhabung komplexer Produkte mit einer Vielzahl von Anforderungen und erlaubt eine schnelle Identifikation der relevanten Use Cases für die folgenden Schritte der Produktentwicklung.
https://doi.org/10.1017/dsj.2025.10019